Abstract
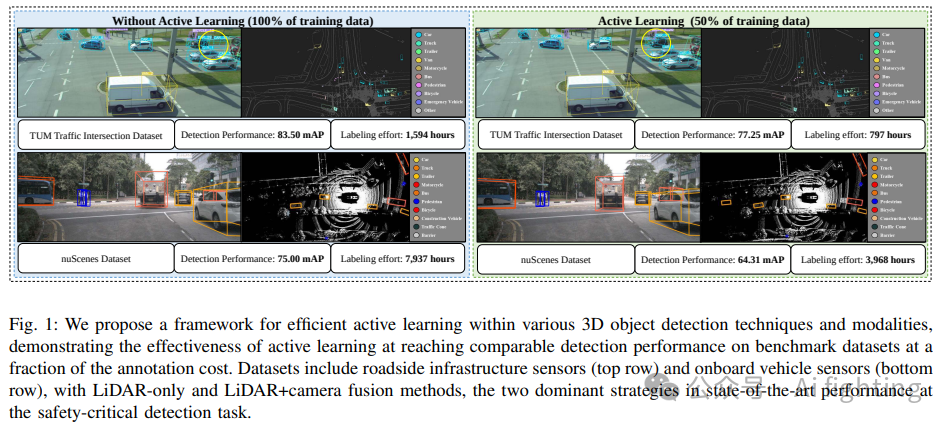
大规模数据集的策划仍然成本高昂且需要大量时间和资源。数据通常需要手动标注,创建高质量数据集的挑战依然存在。在这项工作中,我们使用主动学习填补了多模态3D目标检测研究的空白。我们提出了ActiveAnno3D,这是一种主动学习框架,用于选择最具信息量的训练数据样本进行标注。我们探索了各种持续训练方法,并整合了在计算需求和检测性能方面最有效的方法。此外,我们在nuScenes和TUM交通路口数据集上使用BEVFusion和PV-RCNN进行了大量实验和消融研究。结果表明,在使用TUM交通路口数据集的一半训练数据时,使用PV-RCNN和基于熵的查询策略可以实现几乎相同的性能(77.25 mAP对比83.50 mAP)。在使用一半训练数据时,BEVFusion达到了64.31的mAP,而在使用完整的nuScenes数据集时达到了75.0的mAP。我们将主动学习框架集成到proAnno标注工具中,以实现AI辅助的数据选择和标注,并将标注成本降至最低。最后,我们在我们的网站上提供代码、权重和可视化结果:https://active3d-framework.github.io/active3d-framework。
Introduction
标注过程仍然是一个挑战,尤其是对于3D点云。据文献[17]所述,标注一个精确的3D框需要标注人员超过100秒的时间。这相当于nuScenes数据集的标注时间达到7,937小时。由于深度学习模型需要大量标注数据,创建大规模标注3D数据集在开发强大3D感知模型时是一大挑战。为了缓解这一挑战,主动学习旨在通过查询少量未标注数据的标签来减少标注成本,从而在标注尽可能少的样本的情况下最大化模型性能。尽管主动学习通过选择最具信息量的图像和点云帧显著降低了标注成本,但它也会由于反复的模型训练和评估周期而增加计算开销。
Related Research
主动学习技术大致可分为两类:一种依赖于特定任务的特定模型,另一种则更普遍地作用于数据本身,与数据要解决的问题无关(有时称为“基于多样性的方法”)。尽管这些技术可以结合起来创建一个采样策略,但使用基于任务或模型的主动学习策略的好处在于,理论上所选数据将对所需任务的性能优化。
主动学习在自动驾驶中的应用必须具备以下特点:
多任务:识别对一个任务最优的数据是一个良好的开始,但在实际操作中,如果主动学习的目的是减少标注预算,那么这对于必须使用相同精心策划和采样数据来解决多个任务的自动系统帮助不大——例如轨迹预测,标志和灯光检测与分类,动态目标检测和跟踪,车道检测,车辆地标识别等。幸运的是,多任务一致性测量可以通过考虑多个目标任务的性能来指导采样。
多模态:虽然自动驾驶车辆测试床可能配置了多种传感器,但3D目标检测领域的最新技术,关键在于无碰撞驾驶,利用了LiDAR(用于精确测距)和图像(用于语义实用性)。在撰写本文时,nuScenes 3D目标检测排行榜上的前33个模型都使用了这两种模态(实际上,其中两种在中间位置进一步包括了雷达)。大多数3D检测的主动学习研究不包括视觉模态,即使包括,其图像相关模块也未纳入学习循环。我们在最先进的LiDAR+相机架构上引入了主动学习。
开放集:我们还注意到,自动驾驶领域的数据本质上是开放集,这意味着今天数据集中标注的项目可能并不能完全代表在实际驾驶环境中可能出现的所有项目。标准的主动学习方法在开放集设置中由于标注数据和未标注数据之间的类别分布不匹配而不能有效执行,这也强有力地说明了在主动学习模型的分类阶段重要性,因为分类中的不确定性提供了一种识别开放集类别实例的手段。Safaei等人表明使用封闭集熵在类别概率和距离熵在学习特征上可以是有效的学习策略,能够有效地在未知的开放集池中学习,尽管这尚未应用于自动驾驶数据,因为他们的实验是在CIFAR和TinyImageNet基准上进行的。这进一步激发了我们在自动驾驶领域探索基于熵的主动学习。
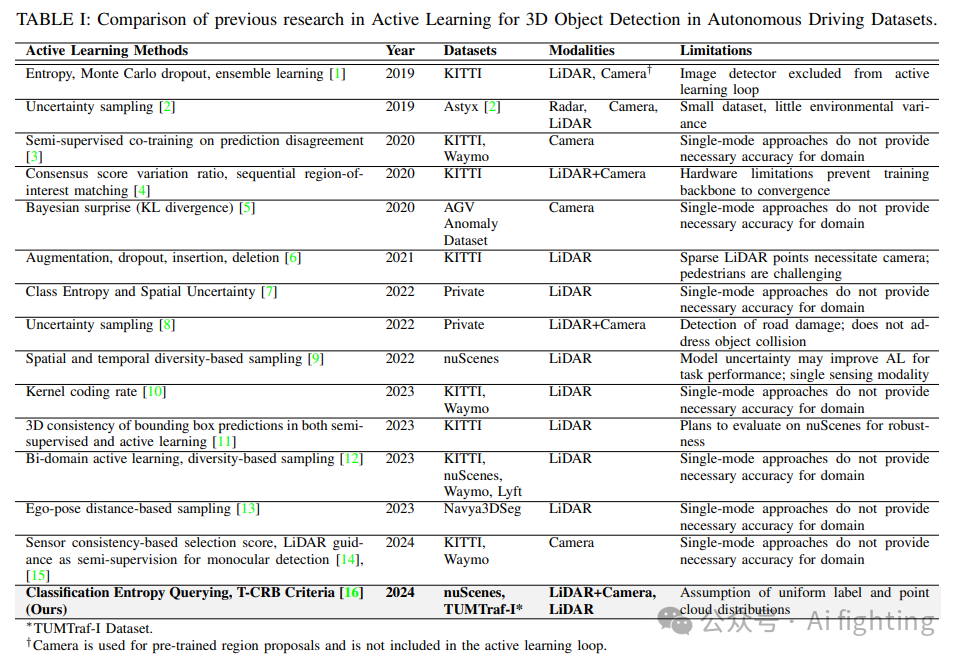
Method
1、采用主动学习进行3D目标检测
3D目标检测对自动驾驶和移动机器人至关重要,但构建精确的3D目标检测器依赖于大量标注数据集的可用性,而在有限的标注预算下,这是一项特别具有挑战性的任务。主动学习提供了一种有前途的解决方案,通过仅查询未标注数据池的一小部分数据的标签来减少标注成本。基于标准的查询选择过程迭代地选择最具信息量的样本进行后续模型训练,直到标注预算耗尽。在此基础上,我们将基于池的主动学习框架部署到一个仅使用LiDAR的两阶段3D目标检测器和一个多模态3D目标检测器上,采用了中的熵查询策略。我们研究了使用持续训练策略来解决主动学习资源消耗大的问题.
2、熵查询: 在主动学习中,查询策略是选择下一个要注释的数据样本的关键。熵查询是一种策略,用于评估模型预测的不确定性。熵 H(X) 使用以下公式计算:
H(X)=−i∑(P(xi)logP(xi))
这里,P(xi) 表示模型分配给类 xi 的概率。高熵表示不确定性较高,表明这些样本对于注释来说是最具信息量的。
3、仅LiDAR的3D物体检测中的主动学习: 首先,使用两阶段的PV-RCNN模型进行仅LiDAR的3D物体检测。在推理阶段,使用各种查询策略,包括基于不确定性、基于多样性和混合方法,每种方法都有其选择信息样本的特定标准。其中一种提到的策略是T-CRB(临时一致性CRB),设计用于从未标记数据池中选择最具信息量的时间一致性点云集。
4、 选择一个目标检测模型
5、持续训练策略采用了一种主动学习方法,其中初始的3D检测器在最初标记的数据集上进行预训练。查询策略通过连续的训练周期识别最具信息量的数据样本,并从“神谕”那里获取标签。随后,使用增强的训练集更新初始模型。然而,这个过程以其时间和资源密集性为特征,因为模型在每个训练周期都会从头开始重新训练,使用不断扩展的标记数据集。此外,这种方法忽略了在先前训练周期中积累的知识。为了解决这一挑战,我们增强了主动训练周期,通过整合多种连续训练策略。
Experiments
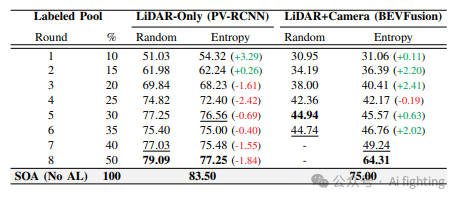
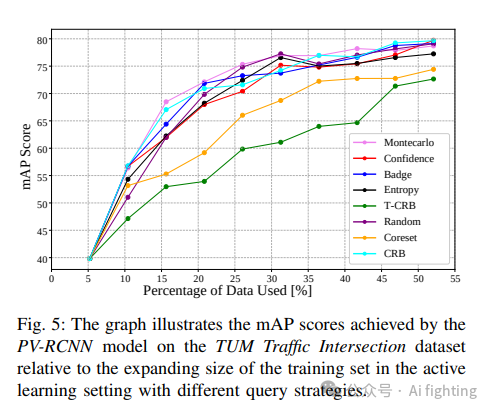
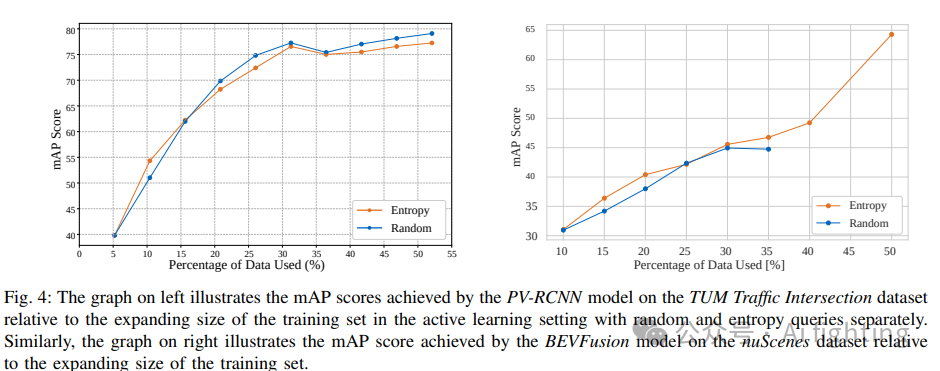
下图提供了与主动学习中各种查询策略相关的3D物体检测性能见解。评估涵盖了诸如BADGE 、CoreSet 、蒙特卡洛抽样、置信度抽样、CRB以及时间修改的CRB(T-CRB)等多种策略。这种分析有助于精确定位最有效的方法,以适应TUM交通十字路口数据集的独特特征。表II中的结果显示,在TUM交通十字路口数据集上,PV-RCNN检测器使用随机抽样查询策略表现优于熵查询策略,如图4左侧所示。然而,在LiDAR+摄像头模型中,情况并非如此。如图4右侧所示,在除第四轮外的每一轮中,熵查询策略都优于随机查询策略。

总结
文章的主要贡献包括:
1、提出了ActiveAnno3D框架,用于选择对训练最有信息量的样本进行标记。
2、探索了不同的持续训练方法,并集成了计算需求和检测性能最高效的算法。
3、在nuScenes和TUM Traffic Intersection数据集上对BEVFusion和PV-RCNN进行了广泛的实验和消融研究。将ActiveAnno3D集成到proAnno标记工具中,以实现AI辅助数据选择和标记,最小化标记成本。
引用:
ActiveAnno3D - An Active Learning Framework for Multi-Modal 3D Object Detection
欢迎关注我的公众号auto_driver_ai(Ai fighting), 第一时间获取更新内容。